
Yandex Crowd Solutions помогли обучить модели для функции редактирования в нейробраузере
96%
качество проверки орфографии и пунктуации в Яндекс Браузере
530К+
человек в месяц пользуются функцией исправления ошибок, реализованной с помощью Yandex Crowd Solutions
5К+
текстов для обучения нейроредактора собрали и исправили за 3 недели силами квалифицированных исполнителей
Продукт и задача
Нейроредактор в Яндекс Браузере — инструмент для работы с текстом. С его помощью пользователи генерируют и редактируют текстовый контент, а еще исправляют орфографические и пунктуационные ошибки. Функцию представили публике в феврале 2024 года.
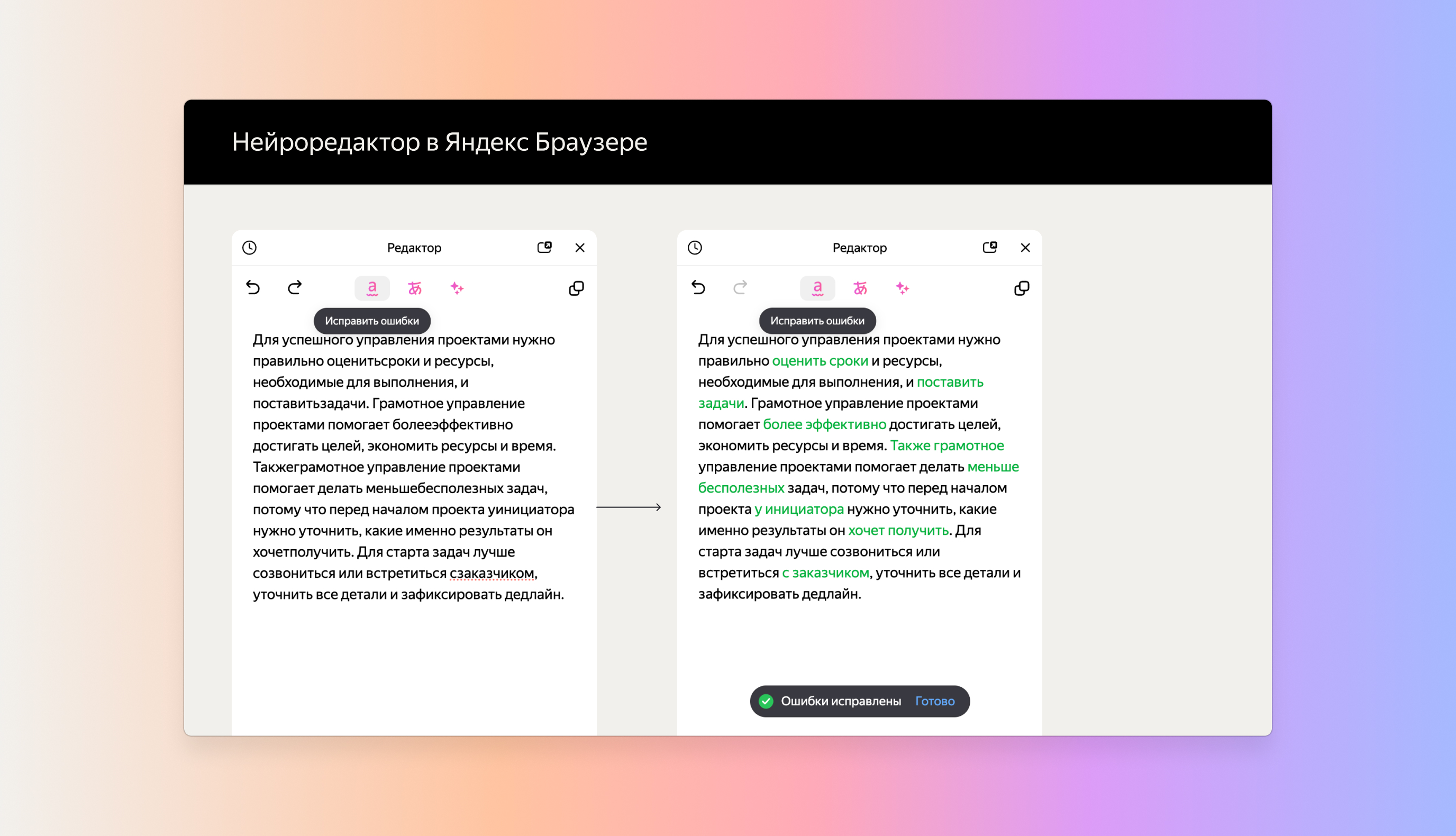
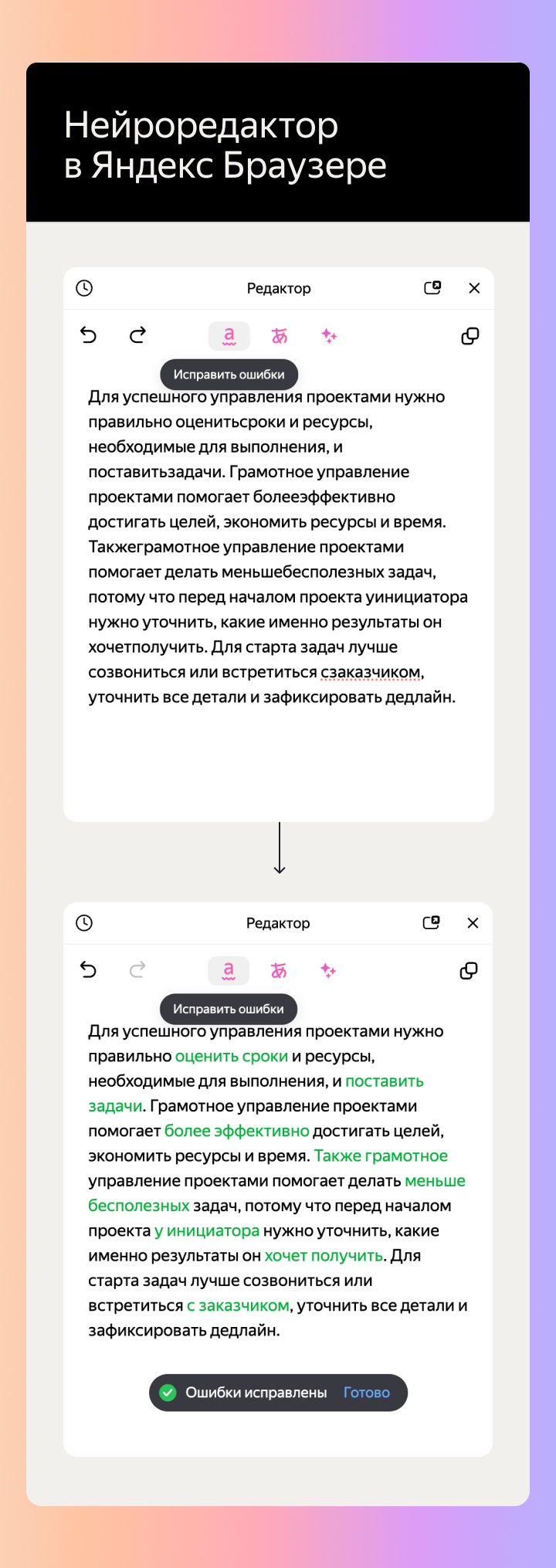
Нейроредактор работает на базе YandexGPT. Перед запуском продукта команда Браузера провела исследование и выяснила, какая помощь с текстами нужнее всего пользователям. Самым популярным оказался запрос на исправление орфографических, пунктуационных и грамматических ошибок.
Так появилась задача: обучить нейросеть исправлять ошибки в тексте, сохраняя его индивидуальный авторский стиль. Для обучения требовалось собрать датасет высокого качества, иначе модель могла бы вносить исправления некорректно.
Чтобы решить эту задачу, разработчики Браузера обратились к Yandex Crowd Solutions.
Решение
В Yandex Crowd Solutions есть команда профессиональных редакторов и корректоров. К подготовке датасета подключили их.
Команда проекта пробовала разные подходы к подбору исходных данных. Начали с эксперимента: редакторов попросили специально добавить ошибки в грамотные тексты. Однако результат не был похож на живую письменную речь, с которой потом должен был работать нейроредактор.
Поэтому для датасета решили собирать реальные примеры интернет-текстов по разным тематикам: IT, домашние рецепты и даже ракетостроение.
Объём подходящих для датасета текстов начинался от 300 символов. Отобранные тексты соответствовали одному или сразу нескольким требованиям:
- присутствуют орфографические ошибки
- присутствуют пунктуационные ошибки
- есть сложные грамматические конструкции
- смысл текста сложно воспринимать
Команда собрала 5000 таких текстов. Затем редакторы Yandex Crowd Solutions исправили в собранных материалах орфографию и пунктуацию. Сленг, бранную лексику, сокращения и междометия редакторы не исправляли по согласованию с командой Яндекс Браузера. Это было нужно, чтобы обучить нейросеть исправлять ошибки без изменения стиля текста и без лишних правок.
Исходные примеры текстов и соответствующие им варианты с исправлениями ошибок Yandex Crowd Solutions передали команде Браузера. На этих данных началось обучение YandexGPT.
Результат
Нейроредактор на основе YandexGPT исправляет орфографические и пунктуационные ошибки с результативностью 96% (по собственным измерениям команды Браузера в сентябре 2024 года). По состоянию на март 2025 года к функции исправления ошибок обращаются более 530 000 пользователей в месяц.
Представленную модель исправления ошибок используют несколько сервисов Яндекса.


Детали проекта
Разметка качества для восьми моделей нейросети
Команда Яндекс Браузера хотела проверить, как разные версии YandexGPT справляются с исправлением ошибок после обучения. Для этого редакторы Yandex Crowd Solutions перепроверяли тексты после исправления ошибок разными версиями нейросети, находили необработанные ошибки и классифицировали их по справочнику Розенталя. Данные о количестве и типах ошибок фиксировали в таблицах. Эту информацию команда Браузера использовала при дообучении моделей.
Со временем команда Яндекс Браузера частично автоматизировала разметку качества: с помощью инструментов на основе алгоритма поиска LCS‑индексов (Longest Common Subsequence) стала отслеживать разницу между версиями текста, обработанными моделями. Это позволило подсчитывать количество ошибок, которые не были исправлены при проверке нейросетью. Однако контрольные датасеты помогали составлять редакторы Yandex Crowd Solutions.
Обучение для поддержки Markdown
Чтобы нейроредактор мог исправлять ошибки, не меняя форматирование текстов, понадобился дополнительный датасет. С его подготовкой также помогла команда Yandex Crowd Solutions. Исполнители добавляли в ранее отобранные тексты элементы форматирования: выделение жирным, курсивом, подчеркивание и другие. После исправления ошибок оценивалось, как часто модель сохраняла элементы Markdown. Обучение продолжалось до тех пор, пока команда Браузера не добилась сохранения markdown-разметки 1:1 в модели исправления.
Вернуться к клиентским кейсам
Поделиться
Кейсы и новости по теме

Учим автомобили Яндекса ездить без водителя
Разметили данные, чтобы сделать автономный транспорт безопаснее

Как улучшить рекомендательную систему на сайте
Помогли повысить качество выдачи вакансий на hh.ru

Как отслеживать работу тысяч партнёров удалённо
Проверяем для Яндекс Go, соответствует ли цвет автомобилей такси заявленному в приложении